



【源码文件,直接赞助下载即可,如需搭建服务,请联系客服,文章末尾有参考视频】
========================================================首先ygbook分为单列表和多栏目匹配方式
区别就是多栏目有分页,可显示全部小说。
先以单列表:http://www.biquge.com/ 举例
前面的什么图片本地化,目标网站域名,编码都不用多说了,都看得懂。其中单列表监控页面为首页,[cate]对应情况取源站顶部分类要中文的,比如玄幻小说 修真小说到最后恐怖小说依次对应本站,如果分类出入太大的,可自行在后台建分类再对应,最大页码为1.
规则列表页码这个很好理解,比如1|1|200的意思就是从第一页开始到200页,每次增加1页。
无缩略图标志一般为nocover,如果不是你看下源站是什么自行改即可。
列表页:链接CSS选择器和列表页:标题CSS选择器
这个怎么选,我们打开首页看到最近更新列表,先取大区域:#newscontent 再取一个区域 .l 区别于下方最新入库的的.r ,最后我们再取我们真正要的区域.s2 a结束,组合就是#newscontent .l .s2 a,很多人喜欢这个样子写,就跟提示差不多 #newscontent li a 有些站是可以的,但是要分清楚。
文章页的各个选项,如果是有360结构化的站那么以下是通用的
标题CSS选择器 :meta[property=og:novel:book_name]|content
作者CSS选择器 meta[property=og:novel:author]|content
缩略图CSS选择器 meta[property=og:image]|content
内容CSS选择器一般为#intro
因为源站简介源码一般为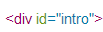 ,如果不是 自行修改intro即可,完结标志不用多说了。
,如果不是 自行修改intro即可,完结标志不用多说了。
章节目录页:区域CSS选择器一般为:#list
自行查看源码就知道了
章节目录页:采集规则也看源码如biquge.com为 ,那么写成
,那么写成 即可。
即可。
如果有这样子的: 你写成
你写成 ,把不要的用[string]代替掉即可。
,把不要的用[string]代替掉即可。
最后章节内容页:内容CSS选择器一般为#content 为什么上面也提到过 自行查看源码就明白了。
通用替换 {filter replace=’hostloc’}笔趣阁{/filter} 如果不替换只删除的话删除hostloc即可。
多栏目以:https://www.snwx8.com/ 为例 这就不解释那么多了,累。。。
规则列表页面为:https://www.snwx8.com/[cate]/.html[cate]
对应情况以网址为准如:sort1 sort2 sort3 对应玄幻 修真 都市 页码自己填
列表页:链接CSS选择器列表页:标题CSS选择器为#newscontent .l .s2 a
此站没有360结构化 所以文章页:标题CSS选择器为 h1 一般都是这个
文章页:作者CSS选择器为.infotitle i 并在文章页:源码预过滤规则填入{filter replace=”}作者:{/filter},多栏目无需写分类。
文章页:内容CSS选择器为 .intro 这有个问题我没解决 .intro虽然可获取 但是获取的值太多 后面的值是不想要的 提示也说了可用|分割过滤 但没搞懂。
文章页:缩略图CSS选择器为#fmimg img|src fmimg为值 img|src为图片
后面就不讲了,和上面差不多
最后如果你有很多采集规则的话我不清楚批量采集会不会重复,但是按ID采集肯定会重复。
其实网上的小说站基本都是杰奇 网址都是按ID的,作者完全可以优化为编写好采集规则后 填入最小ID-最大ID 系统自动生成链接 然后后台慢慢采集即可。然后还有就是去重问题,建议作者增加对比小说名和作者来进行去重,如果相同则不增加小说但增加节点等。。。




![子比主题-给导航菜单添加自定义徽章及多种样式菜单设置方法[图文教程]-创码者资源网](https://ym.cmzym.top/wp-content/uploads/2025/08/20250815110425375-QQ20250815-105919-800x343.png)
















暂无评论内容